蚂蚁EGSS算法破解Test Time Scaling困局 | ACL 2026
蚂蚁EGSS算法破解Test Time Scaling困局 | ACL 2026更聪明的计算远比更多的计算更有效。
来自主题: AI技术研报
6620 点击 2026-06-17 14:06
 搜索
搜索
更聪明的计算远比更多的计算更有效。
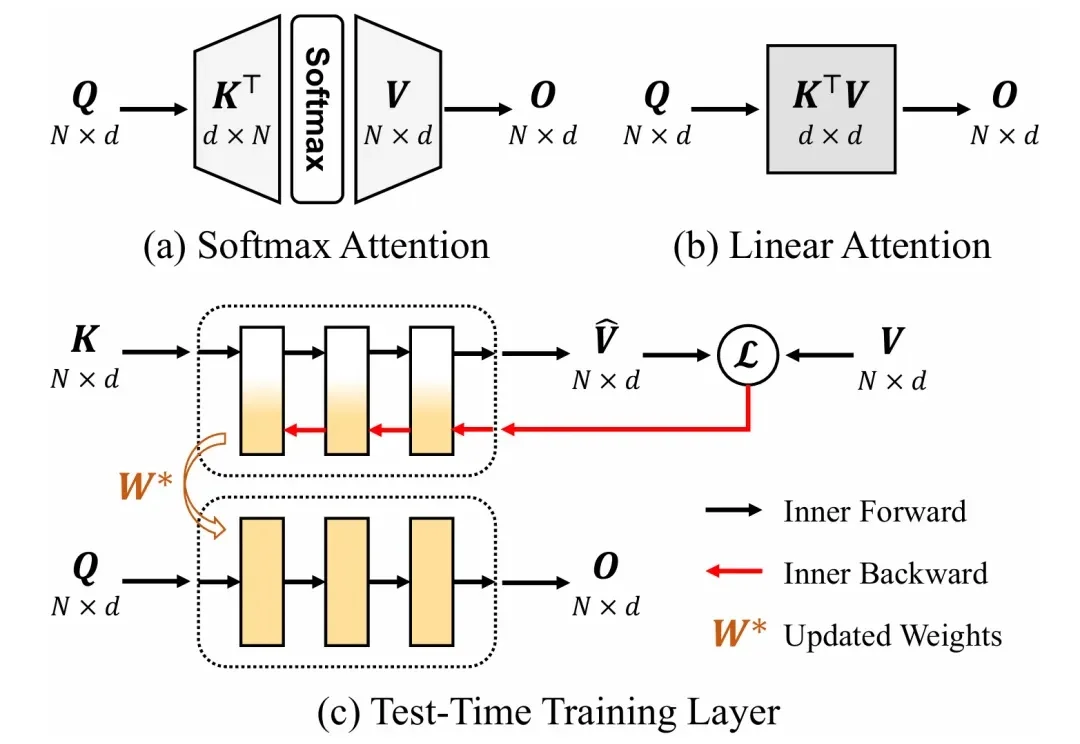
序列建模是大语言模型、计算机视觉等领域的基础共性问题。当前通用的 Transformer 模型计算复杂度随序列长度平方增长,在长序列任务中面临显著的计算挑战。因此,研究者们一直在探索具有线性计算复杂度的高效序列建模方法。
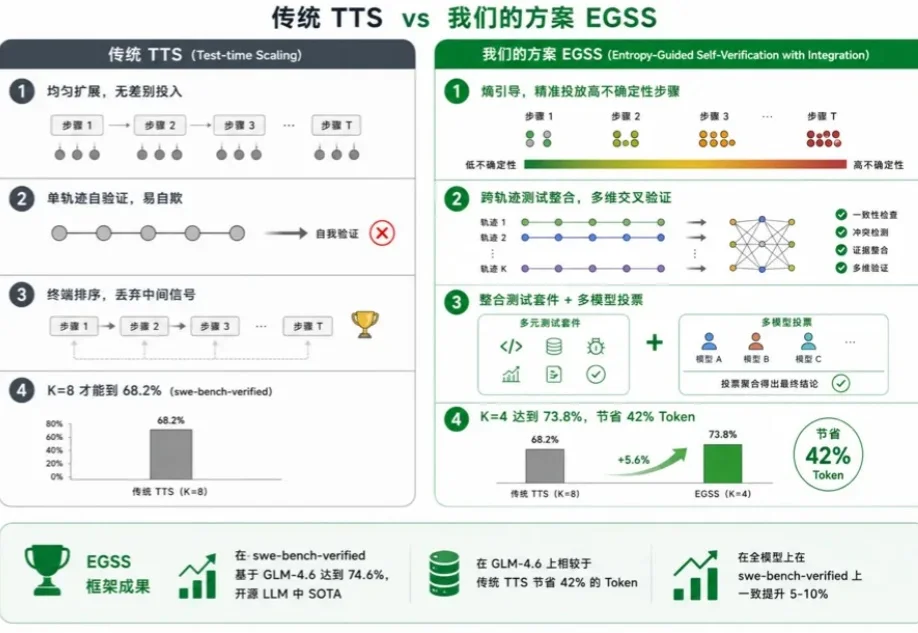
近年来,大模型能力提升的焦点正在从「训练时扩展」转向「推理时扩展」。从 Best-of-N、Self-Consistency 到更复杂的搜索与验证框架,Test-Time Scaling 已经成为提升大模型复杂推理能力的重要范式。

多模态大模型,到底有多“嘴硬”? 浙江大学联合阿里巴巴、香港城市大
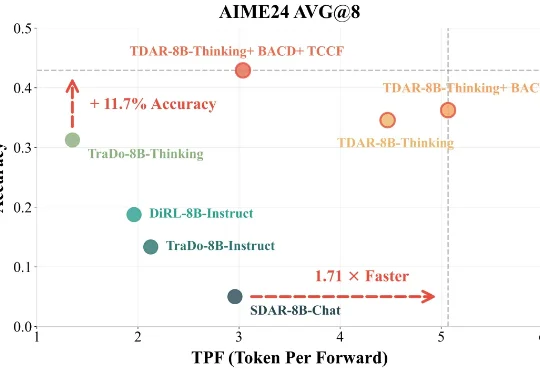
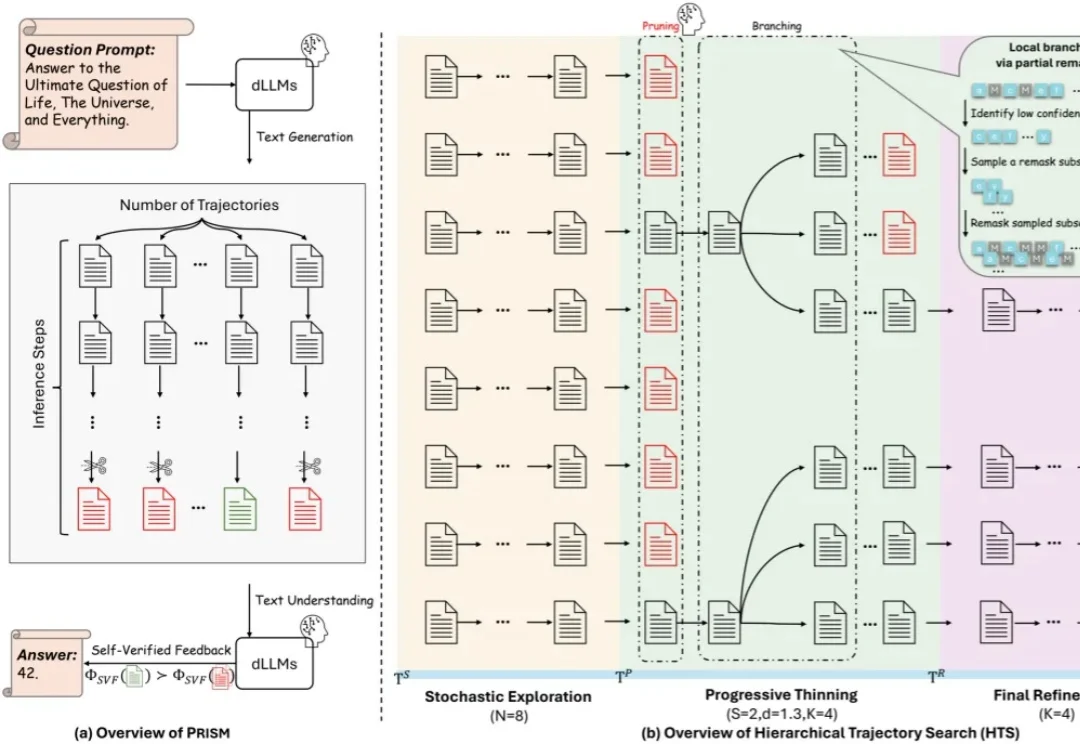
近期,复旦大学 NLP 实验室(FDU NLP)、北京大学知识计算实验室(KCL)联合美团 LongCat Team 提出了一种 Block Diffusion 推理模型 Test-Time Scaling 新框架 TDAR,通过引入 “粗思考,细求证” (Think Coarse Critic Fine, TCCF) 范式与有界自适应置信度解码

在技术如火如荼发展的当下,业界常常在思考一个问题:如何利用 AI 发现科学问题的新最优解?
过去两年,大模型的推理能力出现了一次明显的跃迁。在数学、逻辑、多步规划等复杂任务上,推理模型如 OpenAI 的 o 系列、DeepSeek-R1、QwQ-32B,开始稳定拉开与传统指令微调模型的差距。直观来看,它们似乎只是思考得更久了:更长的 Chain-of-Thought、更高的 test-time compute,成为最常被引用的解释。
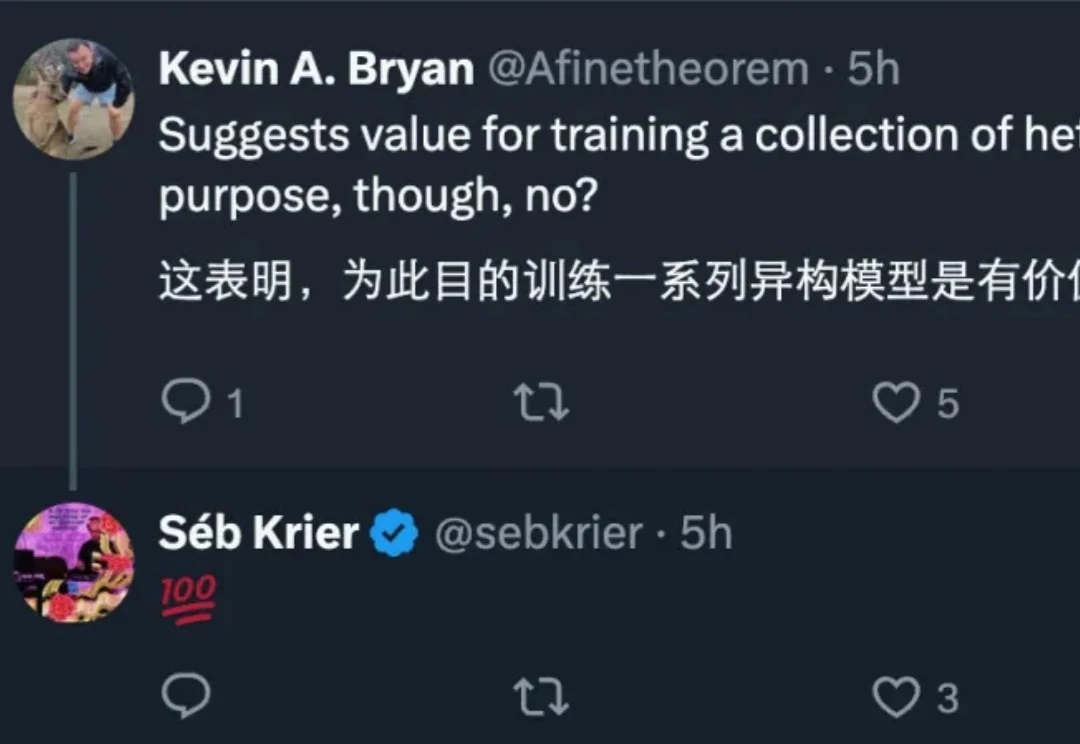
如果说大模型的预训练(Pre-training)是一场拼算力、拼数据的「军备竞赛」,那么测试时扩展(Test-time scaling, TTS)更像是一场在推理阶段进行的「即时战略游戏」。

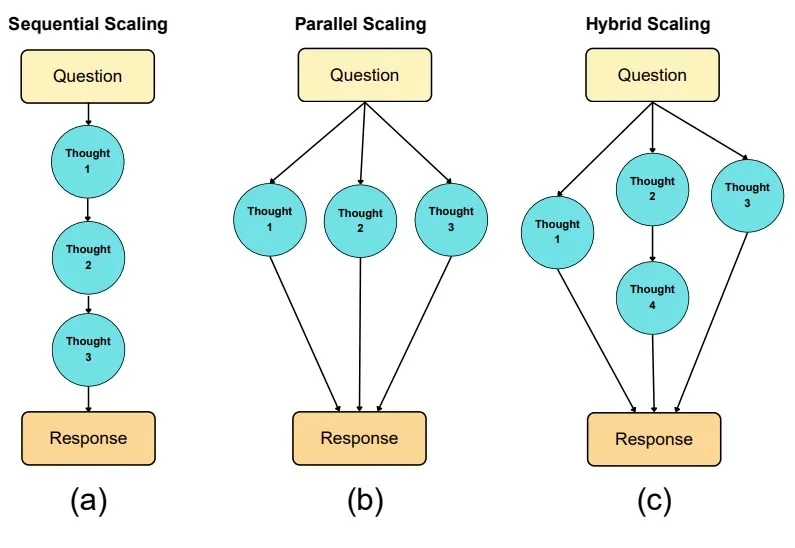
大模型推理的爆发,实际源于 scaling 范式的转变:从 train-time scaling 到 test-time scaling(TTS),即将更多的算力消耗部署在 inference 阶段。典型的实现是以 DeepSeek r1 为代表的 long CoT 方法:通过增加思维链的长度来获得答案精度的提升。那么 long CoT 是 TTS 的唯一实现吗?
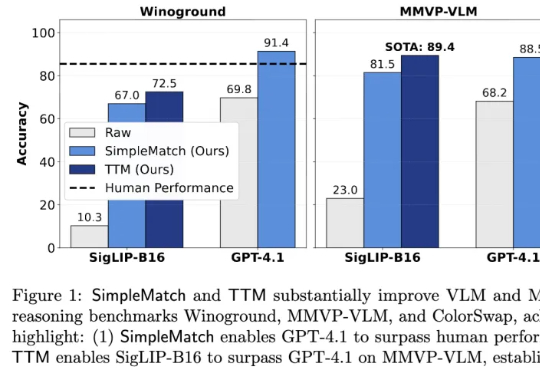
加州大学河滨分校团队发现,AI组合推理表现不佳部分源于评测指标过于苛刻。他们提出新指标GroupMatch和Test-Time Matching算法,挖掘模型潜力,使GPT-4.1在Winoground测试中首次超越人类,0.2B参数的SigLIP-B16在MMVP-VLM基准测试上超越GPT-4.1并刷新最优结果。这表明模型的组合推理能力早已存在,只需合适方法在测试阶段解锁。